29 сентября 2012 г.
Django
Кинсбург
 In English
In English
Встречайте, KinsburgTV!
![]()
Вот и прошло три года с момента запуска первой версии, и два года со второй.
Новый мажорный релиз размещен на новом домене kinsburg.tv, таким образом я решил не отключать старый проект, а развивать новый параллельно.
Новый проект написан на Python и Django, также под капотом находятся Nginx+uwsgi, Scrapy, MySQL, SphinxSearch, Redis, Celery, а для развертывания и поддержки проекта используется virtualenv, supervisor, South и Fabric.
Проект был переписан, так как я последние 3 года программирую на Python и использую Django. Поддерживать и развивать фичи на PHP стало слишком трудоемко, поэтому и принял решение переписать все на Python.
В новый проект я перенес все данные, для паролей пользователей пришлось создать свой хешер "LegacyPasswordHasher", который умеет хранить в старом формате пароли (чтобы не мучать пользователей после миграции), по умолчанию Django использует PBKDF2. Остальные данные перенеслись достаточно легко, хотя чтобы учесть все ньюансы - кода для этого было написано не мало. Не перенес только Викторину, планирую её перенести гораздо позже.
Реализованные новые возможности
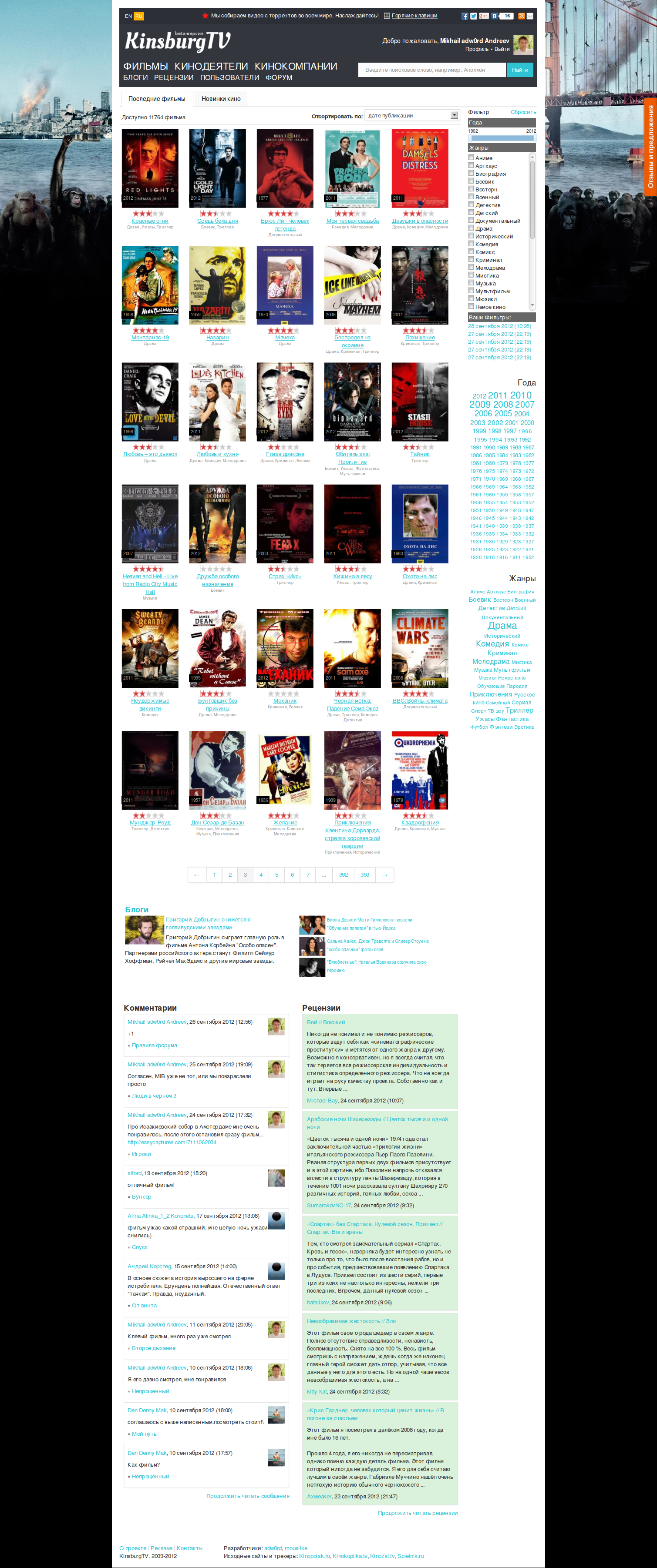
Эти возможности на самом деле - запросы от пользователей за последние год-два, так что реализовал все что просили.
- Новый фильтр (с сортировкой и поиском) без перезагрузки страницы:
- В поиске также, помимо полнотекстового, присутствует поиск по маске.
- В фильтре помимо включения жанра есть игнорирование, для этого надо нажать дважды по жанру и появится "красный крестик" (видео демонстрирующее эту функциональность).
- Новый сервис закладок с возможностью создания своих типов закладок:
- Также есть возможность переносить, удалять и копировать закладки;
- Архитектурой предусмотрено возможность класть в закладки любые объекты (спасибо "django.contrib.contenttypes"), а не только фильмы, но сейчас закладки работают только для фильмов.
- Кинокомпании и страны теперь кликабельны:
- Сейчас есть несколько опубликованных Кинокомпаний, но они будут постепенно добавляться через Scrapy;
- Страны не представлены в меню, но они есть в неоконченном виде, думаю в качестве картинки туда вставлять коллаж из топовых фильмов и небольшой флажок страны сверху.
- Блоги о фильмах, кинозвездах и кинокомпаниях:
- Блоги пока берутся только с сайта www.spletnik.ru и только по теме кино конечно.
- Рецензии на фильмы:
- Пока рецензии беруться с Кинопоиска, но также предусмотрен ручной ввод рецензий и вскоре будет доделан и опубликован удобный интерфейс для ведения рецензий.
- Появилась авторизация через социальные сети, решил что сейчас актуально только Facebook, Вконтаке и Twitter. Подумываю о добавлении Google, Yandex и OpenID, но не уверен что это актуально.
- Авторизация реализована с помощью клёвой библиотеки django-social-auth, до неё пробовал django-ulogin, но сам сервис uLogin мне не понравился (мои сумбурные заметки об этом). На пыхе также обсуждали другие библиотеки, в частности loginza, но отзывы о ней плохие, поэтому даже не пробовал. В любом случае сервисы - это сервисы, и зависимость от сервисов это больше проблема чем зависимость от библиотеки которая проксирует запросы к конечным "соц. сетям".
- Появился интерфейс на английском языке, так как некоторые люди просили меня сделать это, потому что есть множество фильмов с английскими дорожками и они успешно их смотрят;
- Просмотр онлайн через свое приложение django-torrent-stream.
Запланированные возможности
Сейчас в моей Jira порядка 30-40 новых задач для проекта KinsburgTV, в основном они мелкие, типа "Реализовать смену пароля в профиле", но есть и большие фичи:
- Афиша и бронирование билетов на фильмы;
- Реализовать викторины "Угадай фильм по кадру" и "Актёрам и режиссёрам", а также перенести данные по викторине "Угадай фильм по кадру";
- Написать больше тестов, так как сейчас есть только тесты для модулей;
- Реализовать сервис рекомендаций;
- В фильтр добавить:
- Возможность указать Кинодеятелей, Кинокомпании, Страны;
- Выбор аудио дорожки, других параметров Торрента.
- Дополнительные фильтры основанные на закладках:
- Не выводить фильмы которые смотрел (берет данные из системных закладок "Смотрел");
- Не выводить фильмы страницы которых я открывал;
- Не выводить фильмы которые я скачивал.
- Добавлю больше источников для Фильмов.
Немного подробностей
Пауки для Фильмов, Рецензий, Блогов и Кинокомпаний работают на Scrapy, данные пишутся сразу в MySQL, не используя Items (кроме Кинокомпаний), было сделано для ускорения разработки, но код получился не особо красивым. Планирую использовать Items (точнее модифицированнй DjangoItem, об этом напишу когда будет время) и промежуточно хранить данные в MongoDB, так как он хорошо подходит под хранение разнородных данных одного типа.
Celery используется по назначению - выполняет отложенные задачи, такие как подсчет статистики по топикам и бордам на Форуме, отправка писем и т.д.
Фильтры хранят название фильтра (получается псевдо-случайно и имеют префикс "fi", например ) и json-данные (через jsonfield) в MySQL. При запросе по названию достаются значения из БД и применяются в ORM фильтре, после чего получается результирующий QuerySet и он выводится пользователю. Сделано хранение фильтра в БД для того чтобы мы могли после ajax-фильтрации выдать URL который может быть передан от пользователя "A" пользователю "B" и пользователь "B" при заходе на этот URL получит теже данные, который видел пользователь "A".
Ресайз картинок сделан через кастомный тег и ngx_http_image_filter_module. Об этом почти готова небольшая статья-сниппет.
В Redis хранятся сессии и кеш.
Издержки производства
В результате работы над проектом были реализованые некоторые необходимые проекту библиотеки, например:
- django-sphinxsearch который в отличие от django-sphinx умеет создавать нормальный QuerySet, с которым далее можно делать всё что угодно;
- django-ratings - мой форк проекта David Cramer django-ratings, в нём реализован вес для каждого голоса, т.е. суммарные голоса с Кинопоиска или IMDB имеют больший вес чем один пользовательский;
- django-comments-plus - я сразу делал это приложение отдельно в репозитории и оно не связано вообще с проектом, так что нужно только написать тесты и опубликовать в PyPI. Сейчас оно умеет:
- Хранить комментарии и рецензии (отличается от комментария только полем "is_review" и типом рецензии, например "positive"/"negative");
- Для не авторизованных пользователей есть возможность ввести "email", "имя" и конечно комментарий, тогда его комментарий встанет в очередь на премодерацию, а пользователя зарегистрирует в системе и вышлет ему письмо для подтверждения. Таким образом пользователь не остался анонимом, а стал зарегистрированнм пользователем;
- Форма на ajax, по сути только ошибки валидации формы выводятся, а после удачного сабмита происходит редирект, думаю надо еще допилить этот момент;
- Подписка на комментарии и соответсвенно рассылка писем подписчикам. Все подписки приходят с ссылкой на "Usubscribe", также есть веб-интерфейс для отписки от подписок;
- Ветвление комментариев через "Adjacency list" (TODO).
- Для Scrapy и его источников были сделаны доп. библиотеки, например spider с красивым логгированием в stdout, xpath selector для сокращенных форм запроса. Хелперы для Wikipedia, которые чистят сноски, ссылки и т.д.;
- Библиотека Emelya, которая выводит доп. информацию по email, например MX-записи, адрес почтового веб-сервиса и т.п. Для того чтобы можно было сделать интерфейсы более удобными для пользователя (например после отправки письма не только просить пользователя сходить к себе в почту и подтвердить свою регистрацию, но и выводить ему кнопку по которой он попадет в свой почтовый веб-сервис);
- Библиотека для работы с torrent-файлами и Трекерами (пока очень сырая);
- В зачаточном состоянии находится django-infinite-scroll, который по задумке является дополнительным типом для CBV, и реализует бесконечную прокрутку при выводе какого-либо QuerySet;
- Был исправлен в Django множественный DISTINCT для MySQL, но пока мой патч отвергли, так как нет документации, номера задачи и тестов. Но как только появится время я обязательно доведу дело до конца;
- django-torrent-stream для реализации просмотра видео-торрентов на сайте в режиме онлайн;
- Всякие теги и фильтры для человечного вывода информации, простейшие математические функции, thumbnail, goto_url и т.п.
Мне с проектом также помогала mouellke, а именно общее оформление сайта. За что ей большое спасибо!
Вот в принципе и всё что хотел рассказать.
Посетите KinsburgTV прямо сейчас!
Комментарии
А что именно и как кешируешь?
Сайт приятен, фильтр и поиск стали значительно удобнее. Багов пока не нашел, да и не искал.
На волне всех этих судов над торентами и поисковиками по ним не страшно этим заниматься?
А тем временем kinobaza.tv ищет разработчика.
На главной у рецензий сверху тоже скругление добавь. Интересно как ты будешь сливать показатели и трафик с старого сайта.
У меня есть декораторы и менеджер модели (миксин), который перегружает objects.count() и кеширует результат на заданное время.
Также есть кеши на сигналах, как только обработчик сигнала получает сигнал то кеш инвалидируется.
Также через johnny-cache кешируются все QuerySet в Redis. Чтобы Redis не съедал всю память у меня включен "vm-enabled" и ограничение "vm-max-memory 2gb". Я знаю что johnny-cache не лучший вариант, но пока меня он устраивает
Спасибо, буду улучшать по возможности!
Зато их нашел GoogleBot, я правда уже все пофиксил :)
А что именно за "суды над торрентами"? Дай ссылочки, плизз, я не в курсе просто
Там PHP, я его не осилю
Оки, сделаю, спасибо!
Показатели пусть сами растут, на худой конец сделаю "kinsburg.ru" зеркалом, а если это не поможет, то сделаю перманент редирект.
Трафик буду постепенно сливать, сначала на "kinsburg.ru" добавлю сверху баннер, потом посмотрим, крайний вариант - всё тотже редирект :)
goto_url выделил в отдельное приложение https://github.com/adw0rd/django-goto-url
thumbnail выделил в https://github.com/adw0rd/django-nginx-image
Оставьте свой комментарий